The beginning of my Machine Learning journey — Introduction

This is the start of my Machine Learning journey. My plan is to learn from different sources and write my notes here. The idea of these notes is to refer back to a certain topic when I need and also to augment my learning process.
Machine Learning is the science of programming computers so they can learn from data. A simple example of a Machine Learning program is a spam filter which we daily benefit from, in our email client.
Machine Learning is great for:
- Problems for which existing solutions require a lot of rules and fine hand-tuning.
- Complex problems for which there is no solution using a traditional approach.
- Fluctuating environments where manual tuning is impossible (ML system can adapt to new data).
- Getting insights from complex problems and large data sets.
Types of Machine Learning
Machine learning algorithms can be classified into multiple types based on:
- Whether or not they are trained with human supervision.
- Whether or not they can learn incrementally.
- Whether they work by comparing new data points to known data points or by detecting patterns in training data.
Supervised/Unsupervised Learning
This classification based on the amount and type of supervision that the algorithm gets during training. There are four categories in this type of classification:
Supervised Learning
In supervised learning, the training data you feed to the algorithm includes the desired solutions i.e. labels. The algorithm analyzes the pattern of the data against the provided labels. A typical supervised learning task is the spam filter classification. Such a system is trained with many example emails along with their class (spam or ham) and it will learn how to classify new emails. Other algorithms in this category are:
- k-Nearest Neighbors
- Linear Regression
- Logistic Regression
- Support Vector Machines (SVMs)
- Decision Trees and Random Forests
- Neural networks (some neural networks can be unsupervised/semi-supervised)
We will see each one in-depth in the coming posts.
Unsupervised Learning
As the name suggests, the training data is unlabeled. The system tries to learn without any labeled examples. Some of the important unsupervised learning algorithms are:
- k-Means Clustering
- Hierarchical Cluster Analysis (HCA)
- Expectation Maximization
- Visualization algorithms
- Dimensionality reduction
For example, say you have a lot of data about your app’s usage time on a daily basis. You may want to run a clustering algorithm to try to detect groups of similar users and their usage time. You do not tell the algorithm about which group the user belong to. Instead, it finds the connections without your help. For example, it might notice that 30% of your users use the app in the morning for more than 4 minutes compared during the day time. This might help you in targetting the users better say using notifications.
Semisupervised Learning
Some algorithms can handle partially labeled training data, usually a lot of unlabeled data and a little bit of labeled data. This is called semisupervised learning.
Some good examples in this category are photo-hosting services like Google Photos. Once you upload your photos on to the service, it automatically groups them based on the person in the photograph. This is the unsupervised part of the system (clustering). Now all the system need is for you to tell it who these people are. Just one label per person and system will be able to name everyone in every photo, which will be useful in searching for photos.
Most semisupervised learning algorithms are combinations of unsupervised and supervised algorithms. For example
- Deep Belief Networks (DBNs) are based on unsupervised components called Restricted Boltzmann Machines(RBMs) stacked on top of one another.
Reinforcement Learning
This type of learning system, called an agent in this context, can observe the environment, select and perform actions, and get rewards (or penalties) in return. It must then learn by itself what the best strategy is, called a policy, to get the most reward over time. This policy defines what action the agent should choose when it is in a given situation. For example
- Robots use reinforcement learning to learn how to walk.
- AlphaGo used reinforcement learning to beat the world best player in Go.
Batch and Online Learning
Another criterion to classify Machine Learning system is whether or not it can learn incrementally from a stream of incoming data.
Batch Learning
In batch learning, the system is incapable of learning incrementally. It must be trained using all the available data at once. Once the system is deployed into production, it will apply what it has learned. This is also referred to as offline learning. This will generally take a lot of time and computing resources during training.
If you want the system to know about new data (such as a new spam type), you need to train a new version of the system from scratch on the full data set (old data plus new data), then replace the old system with the new one. Fortunately, this whole process of training can be automated fairly easily. So that batch learning system can adapt to change with less human interaction.
This is not the ideal mode of learning always. Specifically, if the device resources are limited (like in case of a smartphone app).
Online Learning
In online learning, the system is trained incrementally by feeding it instances of data sequentially, either individually or by small groups (mini-batches). Each step of training is cheap and fast, so the system can learn about new data on the fly, as it arrives.
This mode of learning is suitable for systems that receive data as a continuous flow (like stock prices) and need to adapt to change rapidly. It is also a good option if you have limited computing resources. A big challenge with online learning is that if bad data is fed to the system, the system’s performance will gradually decline.
Online learning algorithms can also be used to train systems on huge datasets that cannot fit in one machine’s main memory. This is called out-of-core learning.
Instance-based versus Model-based Learning
One more way to categorize Machine Learning systems is by how they generalize. Most machine learning tasks are about making predictions. This means that, given a number of training examples, the system needs to be able to generalize to samples it has never seen before.
Instance-based learning
In this mode of learning, the system simply learns by heart. For example, in the case of a spam filter, the system will flag the emails that are identical to the ones that are already flagged by users. This requires a measure of similarity between two emails. A basic similarity could be to count the number of words they have in common.
This is called instance-based learning where the system learns the examples by heart, then generalizes to new cases using similarity measure.
Model-based learning
Another way to generalize from a set of examples is to build a model of these examples, then use that model to make predictions. This is called model-based learning.
A simple example of this mode of learning is a Linear regression algorithm. This algorithm will try to fit the training data in a linear fashion and then use that to make predictions.
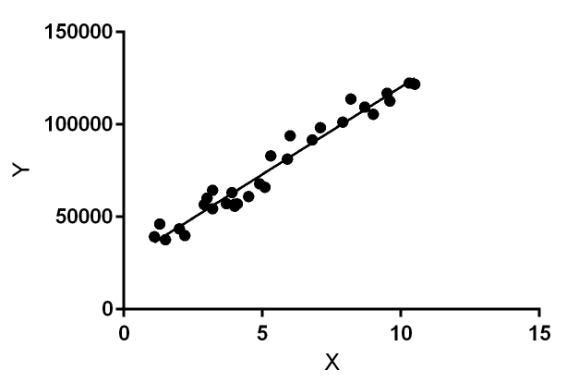
Linear Regression sample (geeksforgeeks.org)
That’s it for this post. We will see about the main challenges in Machine Learning process.